1. 데이터 전처리
먼저 사용할 라이브러리를 불러옵니다.
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor #노드의 평균값
import matplotlib.pyplot as plt
import seaborn as sns
다음 보스턴 데이터 셋을 가져오도록 합니다.
X,y = datasets.fetch_openml('boston', return_X_y=True)
원래는 load_boston() 함수로 데이터 셋을 가져왔지만
특성 B의 흑인 비율이 집 값 예측에 사용되는 것이 인종 차별적이다 판단하여
삭제가 되었습니다.
현재 boston 데이터 셋을 불러오기 위해선 fetch_openml을 사용해야 합니다.

boston 데이터 셋입니다.
각 특성에 대한 설명은 다음과 같습니다.
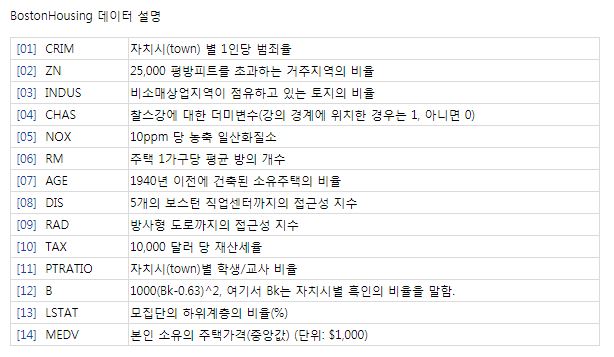
다음 데이터 셋을 훈련 데이터와 테스트 데이터로 나누어줍니다.
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=20,test_size=0.3)
여기서 random_state는 시드 값을 고정해주는 파라미터이고,
test_size는 훈련 데이터와 테스트 데이터의 비율입니다.
2. 모델 훈련
먼저 결정트리 회귀 알고리즘을 사용해 모델을 만들어줍니다.
model = DecisionTreeRegressor(max_depth = 3)
model.fit(X_train,y_train)
max_depth는 결정트리의 깊이를 뜻하며
3개 층으로 된 결정트리 모델을 생성하겠다는 뜻입니다.
from sklearn.tree import plot_tree
plt.figure(figsize=(20,14))
plot_tree(model)
plt.show()
모델을 시각화하여 모델의 모양을 확인합니다.

다음 모델의 정확도를 확인합니다.
train_score = model.score(X_train,y_train)
test_score = model.score(X_test,y_test)
print('학습 세트 R^2 점수: {:.3f}'.format(train_score))
print('테스트 세트 R^2 점수: {:.3f}'.format(test_score))
회귀분석에서는 모형의 적합도를 결정계수로 판단합니다.
학습 세트에서 R^2 점수와 테스트 세트의 R^2 점수를 계산합니다.
R^2은 결정계수로 다음과 같이 구할 수 있습니다.
$$R^{2}=1-\dfrac{\sum \left( 오차 ^{2}\right) }{\sum \left( 편차 ^{2}\right) }$$
오차는 실제값 - 예측값,
편차는 실제값 - 평균값입니다.
R^2이 0~1 사이의 값일때
0은 0점 1은 100점을 뜻합니다.
y_predicted = model.predict(X_test)
예측값을 변수에 저장합니다.
number_of_sample = 55
plt.plot(range(number_of_sample),y_test[:number_of_sample],label = 'real target')
plt.plot(range(number_of_sample),y_predicted[:number_of_sample],label = 'predicted target')
plt.ylabel('price')
plt.legend()
plt.show()
파란색 그래프는 실제 보스턴의 집 값이며,
주황색 그래프는 모델이 예측한 보스턴의 집 값입니다.
비교적 잘 예측했지만 일부 예측값이 실제와 크게 차이가 나는 모습을 볼 수 있습니다.
3. 랜덤 포레스트
랜덤 포레스트 회귀 알고리즘은 여러개의 의사결정 트리를 이용해 값을 예측하는 알고리즘입니다.
랜덤 포레스트는 데이터 셋의 많은 요소들 중 랜덤으로 요소를 선택해 값을 예측합니다.
from sklearn.ensemble import RandomForestRegressor
model2 = RandomForestRegressor(max_depth = 3, n_estimators=200,random_state = 42,)
model2.fit(X_train,y_train)
랜덤 포레스트 회귀 알고리즘 라이브러리를 불러오고,
모델을 생성합니다.
n_estimators는 트리의 개수로 즉, 사용할 결정 트리의 개수를 설정합니다.
트리의 개수가 많다면 성능은 높아지지만 시간이 오래 걸린다는 단점도 있습니다.
train_score2 = model2.score(X_train,y_train)
test_score2 = model2.score(X_test,y_test)
print('학습 세트 R^2 점수: {:.3f}'.format(train_score2))
print('테스트 세트 R^2 점수: {:.3f}'.format(test_score2))
결정트리의 정확도와 비교했을때 더욱 높아진 모습을 볼 수 있습니다.
number_of_sample = 55
plt.plot(range(number_of_sample),y_test[:number_of_sample],label = 'real target')
plt.plot(range(number_of_sample),y_predicted2[:number_of_sample],label = 'predicted target')
plt.ylabel('price')
plt.legend()
plt.show()
그래프를 봤을 때도 비교적 정확하게 예측한 모습을 볼 수 있습니다.
'머신러닝' 카테고리의 다른 글
| [파이썬] 다변수 함수의 수치미분, 선형 회귀와 경사하강법 (0) | 2023.05.22 |
|---|---|
| [파이썬] 합성함수, 체인 룰 , 수치 미분 (0) | 2023.05.18 |
| [인공지능 수학] 미분 공식과 편미분 (0) | 2023.05.11 |
| [인공지능 수학] 미분의 정의 (0) | 2023.05.10 |
| [파이썬] 의사결정 트리( DecisionTree ) (0) | 2023.05.03 |



