1. 데이터 전처리
위 데이터를 다운받아 전처리 과정을 먼저 해줍니다.
import pandas as pd
fish = pd.read_csv('경로')
fish.head()
데이터는 위와 같은 형태를 띄고 있습니다.
print(pd.unique(fish['Species']))
Species 열의 unique값을 확인하면 위와 같습니다.
모두 물고기의 종류를 뜻합니다.
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
print(fish_input[:5])
물고기의 특성을 모두 numpy 행렬로 변경합니다.
fish_target = fish['Species'].to_numpy()
print(fish_target)다음 Species 열 또한 numpy 행렬로 변경합니다.
여기서 Species열의 행렬은 target 데이터이며 물고기의 특성을 저장한 행렬은 input 데이터 입니다.
from sklearn.model_selection import train_test_split
train_input,test_input,train_target,test_target = train_test_split(
fish_input,fish_target,random_state=42)
input 데이터와 target 데이터를 train_test_split을 통해 훈련 데이터와 테스트 데이터로 나눕니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
사이킷 런의 표준전처리 라이브러리를 사용해
훈련 데이터와 테스트 데이터를 전처리 해줍니다.
2. 모델 학습
로지스틱 알고리즘을 사용하기 전 K최근접 이웃 알고리즘을 사용해 보겠습니다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3) #n_neighbors는 이웃의 개수
kn.fit(train_scaled,train_target)
print(kn.score(train_scaled,train_target))
print(kn.score(test_scaled,test_target))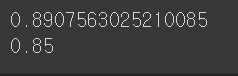
K 최근접 이웃 알고리즘의 파라미터인 n_neighbors는 데이터의 이웃 데이터를 몇 개
볼것인가를 선택하는 파라미터입니다.
정확도가 훈련 데이터는 0.89, 정답 데이터는 0.85입니다.
print(kn.predict(test_scaled[:5]))
test_scaled 변수의 5번째까지 데이터를 예측해 본 결과입니다.
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
predict_prova는 0에서 1까지의 값을 가지며 각 클래스에 대한 확률을 뜻합니다.
가장 확률이 높은 클래스로 예측 값을 출력합니다.
3. 로지스틱 회귀 알고리즘
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
먼저 인덱스 저장 변수에 타겟이 Bream과 Smelt라면 True를 저장합니다.
이 변수에는 True False 값이 들어가게 됩니다.
train데이터와 target 데이터에 Bream과 Smelt의 데이터만 저장합니다.
즉, True값인 데이터만 저장합니다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt,target_bream_smelt)
로지스틱 회귀 알고리즘 모델을 생성해 학습시킵니다.
print(lr.predict(train_bream_smelt[:5]))
train_bream_smelt로 예측한 값입니다.
print(lr.predict_proba(train_bream_smelt[:5]))
predict_proba의 결과입니다.
각 클래스의 확률에 따라 예측한 모습입니다.
lr = LogisticRegression(max_iter=1000,C=20)
lr.fit(train_scaled,train_target)
print('train score: ',lr.score(train_scaled,train_target))
print('test score: ',lr.score(test_scaled,test_target))
Bream과 Smelt만이 아닌 위에서 사용했던 훈련 데이터를 사용했습니다.
정확도가 K 최근접 이웃 알고리즘에 비해 더 높아진 모습입니다.
로지스틱 회귀 알고리즘의 파라미터인 max_iter는 사용할 cpu 개수 이고,
C는 Cost funtion으로 높은 코스트 값을 줄 수 록 더 복잡한 훈련을 합니다.
이 파라미터로 과대 적합과 과소 적합을 해결할 수 있습니다.
print(lr.predict(test_scaled[:5]))
위에서 예측했던 결과와는 조금 다르게 예측한 모습입니다.
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba,decimals=3))
predict_proba의 값입니다.
K 최근접 이웃 알고리즘의 predict_proba에서는 확률 값이 1이 나오는 경우도 있었는데
1이 나온다면 사실상 과대적합이라고 보시면 됩니다.
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision,decimals = 2))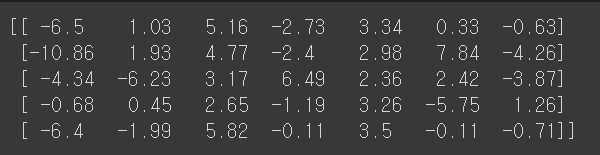
decision_function의 값입니다.
decision_function은 결정 함수로, 각 샘플이 하나의 실수 값을 반환합니다.
이 값은 각 데이터가 양성 클래스 1에 속한다고 믿는 정도입니다.
-는 음의 클래스로 다른 클래스로 믿는 정도를 뜻합니다.
'머신러닝' 카테고리의 다른 글
| [파이썬] 딥 러닝 ANN perceptron 알고리즘 (0) | 2023.09.07 |
|---|---|
| [파이썬] scikit-learn 기초 사용법 (0) | 2023.09.04 |
| [파이썬] 분류 알고리즘( 로지스틱 회귀, 시그모이드) (0) | 2023.05.24 |
| [파이썬] 다변수 함수의 수치미분, 선형 회귀와 경사하강법 (0) | 2023.05.22 |
| [파이썬] 합성함수, 체인 룰 , 수치 미분 (0) | 2023.05.18 |



